
Reaction volumes have been in all measures 100 ul per very well. In Western blotting, samples corresponding to 100 or 500 ul of growth medium and 50 ul bacterial culture were analyzed in a 20% SDS Webpage gel and transferred onto 0. two um nitrocellulose membranes. The detection was done employing anti FLAG antibody and alkaline phosphatase conjugated anti mouse antibody, SPR assay The interaction involving purified His polypeptides and Fn as well as Fg was analyzed by SPR engineering using the Biacore T100 instrument, CM5 sensor chips and amine coupling chemistry in accordance to your manufac turers directions, Single cycle kinetics was applied in the measurements, Briefly, ligands have been diluted in sodium acetate, pH 4. 5 to thirty ug ml and 80 ug ml and applied onto activated sensor chip surface at movement charges ten ul min for seven min with Fg and five ul min for 9 min with Fn. His polypeptides utilized as analytes at concentrations of 0.
five uM, one. 0 uM, one. 5 uM, two. 0 uM and 2. five uM in PBS were injected at a movement fee of thirty ul min working with PBS as a operating buffer. Regenera tion in the surface was completed among the different ana lytes using 10 mM glycine, pH two. three for Fg and five mM NaOH for Fn. manage samples had been employed to confirm that regeneration didn’t affect the binding. PCR screening and sequencing within the clones Colony PCR was applied to estimate the cloning efficiency, i. e. the% selleck chemicals insert carrying transformants of all transformants within the main genomic library, from 200 randomly picked colonies and also to estimate the average insert size of 200 ran domly picked insert containing clones. The colony PCR was carried out applying Dynazyme II DNA polymerase, the PCR primers 017F and 028R purchased from Medprobe shown in Figure 1A, recombinant bacterial cells as templates, and applying regular recombinant DNA ways, The insertions inside the 1663 Ftp clones have been amplified by PCR applying the primers 025F and 028R as well as the recombinant plasmids as templates.
The inserts were then sequenced in each direc tions using the primer 017F for the initially sequence batch and primer 071R for the sec ond batch, The primers, which had been made to flank the cloning web-site in vector pSRP18 0 working with the sequences of E. coli MG1655 and pBR322, were bought pop over to this site from Medprobe or Biomers. Bioinformatics examination of your cloned S. aureus sequences The sequences obtained from your insertions within the Ftp library were in contrast towards the genome and gene sequences of S. aureus NCTC 8325 working with essential nearby alignment search tool, BLASTN, By accepting pair smart alignments with no less than 95% sequence identity and of length at the very least thirty nt, a hit was recorded for 1446 and 1538 query sequences during the first and 2nd sequence batch, respectively.
Response volumes were in all measures 100 ul per very well In We
Reply
 melanin compounds, oxidative and nitrosative strain defense mechanisms, cell adhesion compounds, precise secreted items, arginine catabolism, cell surface com place, and people genes which might be preferentially expressed while in the parasitic yeast phase, Since the transition of these dimorphic fungi from a mycelial to a yeast phase is needed for virulence, this latter category has received considerably attention. For genomic research from the species of H. capsulatum and P. brasiliensis, a big amount of differentially expressed genes are already iden tified with all the transi tion for the pathogenic yeast phase, These genes fall right into a variety of functional classes and have pro vided a valuable resource for present research of phase precise gene expression in these species. Further study in the existing yeast EST database produced for O. novo ulmi and its comparison to your EST library constructed for your mycelia development phase of this species should permit the detection of phase particular gene expression.
melanin compounds, oxidative and nitrosative strain defense mechanisms, cell adhesion compounds, precise secreted items, arginine catabolism, cell surface com place, and people genes which might be preferentially expressed while in the parasitic yeast phase, Since the transition of these dimorphic fungi from a mycelial to a yeast phase is needed for virulence, this latter category has received considerably attention. For genomic research from the species of H. capsulatum and P. brasiliensis, a big amount of differentially expressed genes are already iden tified with all the transi tion for the pathogenic yeast phase, These genes fall right into a variety of functional classes and have pro vided a valuable resource for present research of phase precise gene expression in these species. Further study in the existing yeast EST database produced for O. novo ulmi and its comparison to your EST library constructed for your mycelia development phase of this species should permit the detection of phase particular gene expression.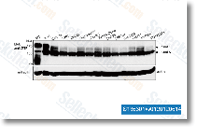 descriptions for prospective transport roles in metabolic pathways, and sequence homology with known PDB structures of ligand bound proteins. A Higher data verification assignment indicates the FTSA ligand binding outcome is supported by really good quality data and by two or extra external sources of practical validation, A Reasonable data verification assignment indicates the FTSA ligand binding outcome is supported by one external supply of functional validation whereas a Minimal data verification assignment indicates basically high self-confidence FTSA ligand mapping information. The end result of this screening approach may be the identi fication of exact roles for transporter SBPs. The spec trum of ligands mapped to your transporter binding proteins incorporate prevalent functionalities linked with several bacterial organisms at the same time as certain abilities linked to the ecological niche that present insight into the extraordinary metabolic diversity of R.
descriptions for prospective transport roles in metabolic pathways, and sequence homology with known PDB structures of ligand bound proteins. A Higher data verification assignment indicates the FTSA ligand binding outcome is supported by really good quality data and by two or extra external sources of practical validation, A Reasonable data verification assignment indicates the FTSA ligand binding outcome is supported by one external supply of functional validation whereas a Minimal data verification assignment indicates basically high self-confidence FTSA ligand mapping information. The end result of this screening approach may be the identi fication of exact roles for transporter SBPs. The spec trum of ligands mapped to your transporter binding proteins incorporate prevalent functionalities linked with several bacterial organisms at the same time as certain abilities linked to the ecological niche that present insight into the extraordinary metabolic diversity of R.