
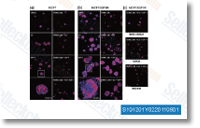
Constant with this particular, when purified human fibrocytes have been intravenously transferred to SCID mice that had been exposed to both bleomycin or saline, higher numbers of human CD45 Col1 CXCR4 fibro cytes were observed in bleomycin challenged lungs as in comparison to saline treated controls. In examining the chemokine receptor profile of circulat ing CD45 Col1 cells in mice, we’ve found that the two in normal mice and animals challenged with bleomycin, CXCR4 would be the most generally expressed surface receptor, remaining present in roughly 70% from the cells. Additionally, CXCL12, the ligand for CXCR4, is expressed while in the lungs and is induced immediately after intrapulmonary administra tion of bleomycin inside 1 day and then stays ele vated for your subsequent 19 days, the dynamics of this expression consequently are constant that has a function for CXCL12 in recruiting CXCR4 fibroytes towards the lungs.
Indeed, in vivo neutralization of CXCL12 resulted in diminished quantity of lung CD45 Col1 CXCR4 fibro cytes and also a SMA expressing myofibroblasts selleck as well as decreased lung collagen written content and attenuated pulmonary fibrosis by histologic morphometric analysis, but did not influence the number of lung neutrophils, macrophages, CD4 and CD8 T cells or NK cells. Constant with this, pharmacological antagonism of CXCR4 also results in reduced lung fibrocyte numbers and pulmonary fibrosis in response to bleomycin. Operate by other groups has examined the part of other mechanisms in recruitment of fibrocytes to your lungs in animal designs of lung fibrosis.
Utilizing a model of intrapul monary fluorescein isothiocyanate induced lung fibrosis, fibrocytes have been isolated from lung tissue and bronchoal veolar lavage just after in vitro culture. These cells expressed CXCR4, CCR5, CCR7 and CCR2 and migrated in response to CCL2 and CCL12 ligands. CCR2 deficient mice treated with intratracheal investigate this site FITC were identified to get decrease levels of fibrocytes within the lung and less fibrosis as when compared with wildtype counterparts, and effect that was later observed to be independent of CCL2, but was attributed to another CCR2 ligand, CCL12. CCR2 can be very expressed on cells on the mononuclear phago cyte lineage like monocyte, macrophage and dendri tic cell populations, even so, and lowered lung fibrosis in response to bleomycin in CCR2 knockout animals corre lated using a substantial reduction in these cells also as inflammatory cytokines during the bronchoalveolar lavage fluid, it’s consequently not clear no matter whether the observed impact in CCR2 deficient animals is attributable to fibro cytes or other cell populations.
Fibrocyte influx on the lung inside the bleomycin model has also been linked to your CCL3 CCR5 chemokine axis, interestingly, this effect was asso ciated with reduced lung expression of lung CXCL12 expression from the lungs of CCL3 and CCR5 deficient ani mals, suggesting that the impact of CCL3 CCR5 may perhaps be mediated by way of the CXCL12 CXCR4 axis.
Consistent with this, when purified human fibrocytes had been int
Reply
 Yeastract as the reference. As shown in Table 5, iBMA prior out performed the other iBMA based mostly solutions, yielding a TPR of 71. 13% averaged over 20 replications. set of promising designs from which to draw inference, the weights of that are calibrated from the external bio logical knowledge. Our approach infers sparse, compact and accurate networks upon the input of the acceptable estimate of network density from each real and simu lated data. It does not place a hard restrict about the amount of regulators per target gene, in contrast to another approaches, this kind of as Bayesian network approaches that impose this constraint to cut back the computational burden.
Yeastract as the reference. As shown in Table 5, iBMA prior out performed the other iBMA based mostly solutions, yielding a TPR of 71. 13% averaged over 20 replications. set of promising designs from which to draw inference, the weights of that are calibrated from the external bio logical knowledge. Our approach infers sparse, compact and accurate networks upon the input of the acceptable estimate of network density from each real and simu lated data. It does not place a hard restrict about the amount of regulators per target gene, in contrast to another approaches, this kind of as Bayesian network approaches that impose this constraint to cut back the computational burden.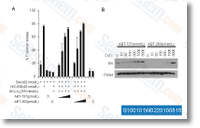 The price of amino acid substitution and dN dS ratio have been calculated using PROTDIST and CodeML, respectively.
The price of amino acid substitution and dN dS ratio have been calculated using PROTDIST and CodeML, respectively. grouped with each other according to their intersite distances to identify the common pharmacophore.
grouped with each other according to their intersite distances to identify the common pharmacophore.